Kubeflow 1.2 release announcement
Kubeflow 1.2 Blog Post
Special Message from Kubeflow Founders
Three years (!!) ago, we (Jeremy Lewi, Vish Kannan and David Aronchick) stood on stage at Kubecon to introduce Kubeflow for the first time. We could not have possibly imagined what would have come about - thousands of GitHub stars, tens of thousands of commits and a community that has built the most flexible and scalable platform for machine learning. And, best of all, it’s not backed by an enormous company that requires you to “upgrade” in order to use it; we gave it all away for free! Here’s to everything you all have done and we could not be more excited about the NEXT three years (and the three years beyond that). Thank you!
Announcing Kubeflow v1.2 release
The Kubeflow Community’s delivery of the Kubeflow 1.2 software release includes ~100 user requested enhancements to improve model building, training, tuning, ML pipelining and serving. This post includes a Release Highlights Section, which details significant 1.2 features as contributed by the Kubeflow application working groups (WG), SIGs, and ecosystem partners. The Kubeflow 1.2 changelog provides a quick view of the 1.2 deliveries.
The Release was validated, tested and documented by the developers, and the Release is now being validated, tested and documented by users, cloud providers and commercial support partners on popular platforms i.e. AWS, Azure, GCP, IBM, etc. The Community is working on a more sustainable approach to owning and maintaining test infrastructure.
For Release 1.2, AWS has built and contributed a shared test-infra, which provides WG owners with enough permissions to identify problems, and test proposed solutions to completion. Currently, most WGs (AutoML, Training-Operators, KFServing, Deployments, Manifests) have already migrated their tests on this solution. As a result, the test-infra blocking time has fallen significantly, which is good for users and contributors.
Getting Involved
The Community continues to grow and we invite new users and contributors to join the Working Groups and Community Meetings. The following provides some helpful links to those looking to get involved with the Kubeflow Community:
- Join the Kubeflow Slack channel
- Join the kubeflow-discuss mailing list
- Attend a Weekly Community Meeting
- Review the Working Group Meeting Notes in Release Highlights Section (as the Notes include great discussions and meeting times)
If you have questions and/or run into issues, please leverage the Kubeflow Slack channel and/or submit bugs via Kubeflow on GitHub.
What’s next
The Community has started discussions on Kubeflow 1.3. Arrikto has agreed to lead the 1.3 Release Management process and the Community will continue to capture input from users and contributors as features are defined, developed and delivered. Onward and upward!
Special thanks to Constantinos Venetsanopoulos (Arrikto), Animesh Singh (IBM), Jiaxin Shan (ByteDance), Yao Xiao (AWS), David Aronchick (Azure), Dan Sun (Bloomberg), Andrey Velichkevich (Cisco), Matthew Wicks (Eliiza), Willem Pienaar (Feast), Yuan Gong (Google), James Wu (Google), Jeremy Lewi (Google), Josh Bottum (Arrikto), Chris Pavlou (Arrikto), Kimonas Sotirchos (Arrikto), Rui Vasconcelos (Canonical), Jeff Fogarty (US Bank) , Karl Shriek (AlexanderThamm), and Clive Cox (Seldon) for their help on 1.2 and this post.
Release Highlights Section
Working Group: AutoML / Katib
Working Group Meeting Notes: Katib Working Group Meeting Notes
Overall benefit: Better model accuracy, Better infrastructure utilization
Overall description: Katib 0.10 with the new v1beta1 API has been released in Kubeflow 1.2. Automated configuration of Hyperparameters to deliver more accuracy models that use less infrastructure, AutoML / Katib simplified the process of finding the optimized set of parameters for your model with Early Stopping techniques. Possibility to orchestrate complex pipeline during Katib Experiment with custom Kubernetes CRD support.
Feature Name: Early Stopping
Feature Description: Save your cluster resources by using Katib Early Stopping techniques. Allow to use the Median Stopping Rule algorithm.
Feature Benefit: You don’t need to modify your training source code to use the feature! Early Stopping can be used with every Katib algorithm.
Feature Name: Support custom CRD in the new Trial template.
Feature Description: You are able to follow two simple steps to integrate your custom Kubernetes resource in Katib. Flexible way to send your hyperparameters in the new Trial template design, which is a valid YAML.
Feature Benefit: Define Tekton Pipeline in your Katib experiment. You are able to pass hyperparameters even if your model config is a JSON scikit learn Pipeline.
Feature Name: Resume Experiments
Feature Description: Implementation of the various methods to resume Katib Experiments. Save the Experiment’s Suggestion data in the custom volume. Use Katib config to modify your volume settings.
Feature Benefit: Free your cluster resources after your Experiment is finished.
Feature Name: Multiple Ways to Extract Metrics
Feature Description: You can specify metrics strategies for your Experiment. Katib computes the Experiment objective based on these values. You are able to view detailed metric info for each Trial.
Feature Benefit: Get correct optimisation results when your model produces necessary value at the final training step.
Working Group: KFServing
Working Group Meeting Notes: KFServing Working Group Meeting Notes
Overall benefit: KFServing enables serverless inferencing on Kubernetes and provides performant, high abstraction interfaces for common machine learning (ML) frameworks like TensorFlow, XGBoost, scikit-learn, PyTorch, and ONNX to solve production model serving use cases.
Overall description: Kubeflow 1.2 includes KFServing v0.4.1, where the focus has been on enabling KFServing on OpenShift and additionally providing more features, such as adding batcher module as sidecar, Triton inference server renaming and integrations, upgrading Alibi explainer to 0.4.0, updating logger to CloudEvents V1 protocol and allowing customized URL paths on data plane. Additionally, the minimum Istio is now v1.3.1, and KNative version has been moved to KNative 0.14.3. More details can be found here and here
Feature Name: Add batcher module as sidecar #847 @zhangrongguo
Feature Description: KFServer Batcher accepts user requests, batch them and then send to the “InferenceService”. Batcher Feature Description
Feature Benefit: Faster response time to inference requests, and Improve infrastructure utilization
Feature Name: Alibi explainer upgrade to 0.4.0 #803 @cliveseldon
Feature Description: The enhancements include a KernelSHAP explainer for black-box model SHAP scores and documentation for the LinearityMeasure algorithm. This delivery includes a new API for explainer and explanation objects, which provide a variety of improvements, but are breaking changes.
Feature Benefit: This delivery improves the ability to understand which features impact model accuracy along with improving operations.
Feature Name/Description : Triton inference server rename and integrations #747 @deadeyegoodwin
Working Group: Pipelines
Working Group Meeting Notes: http://bit.ly/kfp-meeting-notes
Overall benefit: Simplify process of creating a model when you have new data and new code
Overall description: Kubeflow Pipelines is a platform for building and deploying portable, scalable machine learning (ML) workflows based on containers. The Kubeflow Pipelines platform consists of:
- A user interface (UI) for managing and tracking experiments, jobs, and runs.
- An engine for scheduling multi-step ML workflows.
- An SDK for defining and manipulating pipelines and components.
- Notebooks for interacting with the system using the SDK.
The following are the goals of Kubeflow Pipelines:
- End-to-end orchestration: enabling and simplifying the orchestration of machine learning pipelines.
- Easy experimentation: making it easy for you to try numerous ideas and techniques and manage your various trials/experiments.
- Easy re-use: enabling you to re-use components and pipelines to quickly create end-to-end solutions without having to rebuild each time
Kubeflow Pipelines is stabilizing over a few patch releases. At the same time, we made a lot of progress at standardizing the pipeline IR (intermediate representation) which will serve as a unified pipeline definition for different execution engines.
Feature Name: Kubeflow Pipelines with Tekton backend available
Feature Description: After an extensive effort, we have Kubeflow Pipelines running on Tekton end-to-end and available in open source. Additionally it’s available as default with Kubeflow deployment on IBM Cloud, and can be deployed on OpenShift.
Feature Benefit: Tekton support
If you are an existing user of Tekton, or are a fan of Tekton, or running OpenShift Pipelines, get Kubeflow Pipelines running on top of it. More details here
https://developer.ibm.com/blogs/kubeflow-pipelines-with-tekton-and-watson/
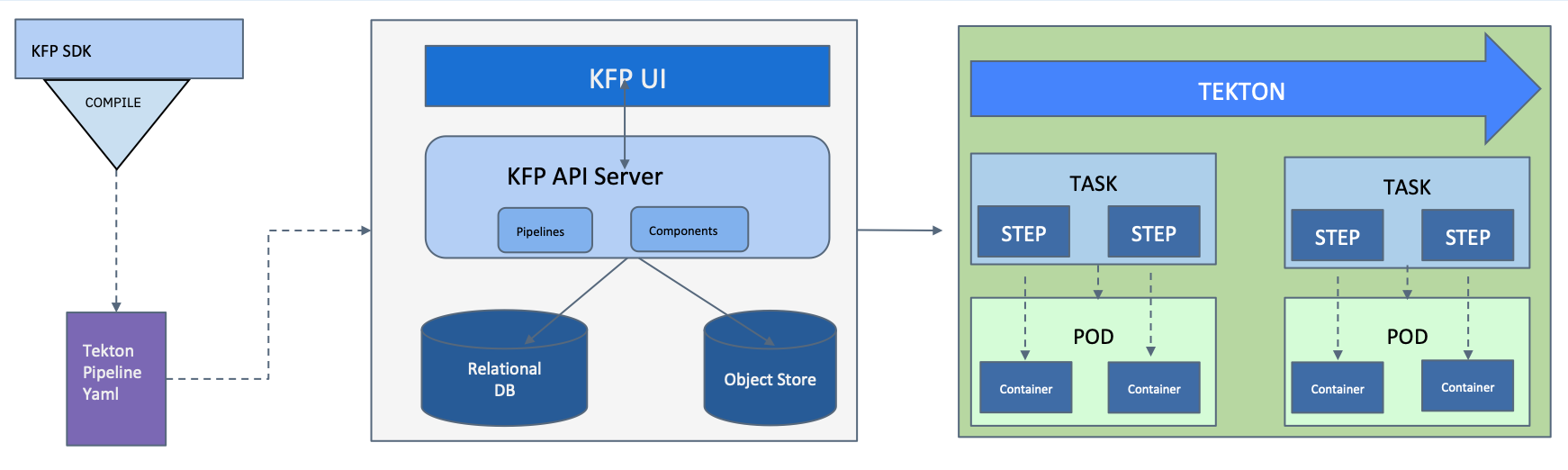
Feature Name: stabilizing Kubeflow Pipelines 1.0.x
Feature Description: We are stabilizing Kubeflow Pipelines over a few patch releases: Kubeflow Pipelines 1.0.4 Changelog ~20 fixes and ~5 minor features.
Working Group: Notebooks
Working Group Meeting Notes: coming soon
Overall benefit: Interactive, experimental coding environment for model development
Overall description: Notebooks provide an advanced, interactive coding environment that users and teams can share and leverage kubernetes namespaces for isolation and resource utilization
Feature Name: Affinity/Toleration configs, #5237
Feature Description: Adds the ability for Kubeflow administrators to set groups of Affinity/Toleration configs which users can pick from a dropdown.
Feature Benefit: Allows more fine-grained selection of how Notebook pods are scheduled.
Feature Name: Refactor Notebooks Web App
Feature Description: The details of the refactoring are defined in these deliveries:
- Common code between the different python backends, #5164
- Create an Angular Library with common frontend code, #5252
- Refactor the JWA backend to utilize common code, #5316
- Initialize the Jupyter web app frontend in crud-web-apps, #5332
Feature Benefit : Refactoring will enable an easier future integration with other web apps - Tensorboard, volume manager.
Feature Name: Stop and Restart Notebooks while maintaining state, #4857 #5332
NOTE: The artifacts for the updated Notebooks web app will be available in 1.2.1 or later
Feature Description: Implementation of a “shut down server” button in the central dashboard that scales the stateful set for the server down to zero and a “start server” button that scales it back up again.
Feature Benefit: Save work, save infrastructure resources
Working Group: Training-Operators
Working Group Meeting Notes: coming soon
Overall benefit: Faster model development using operators that simplify distributed computing
Feature Name: The Training Operator contributors provided the following fixes and improvements in Kubeflow 1.2:
- Update mxnet-operator manifest to v1 (#1326, @Jeffwan)
- Correct XGBoostJob CRD group name and add singular name (#1313, @terrytangyuan)
- Fix XGBoost Operator manifest issue (#1463, @Jeffwan)
- Move Pytorch operator e2e tests to AWS Prow (#305, @Jeffwan)
- Support BytePS in MXNet Operator (#82, @jasonliu747)
- Fix error when conditions is empty in tf-operator (#1185, @Corea)
- Fix successPolicy logic in MXNet Operator (#85, @jasonliu747)
SIG: Model Management
Overall benefit: The ability to find model versions and their subcomponents including metadata
SIG Meeting Notes: Model Management SIG Meeting Notes
Overall description: The SIG was initiated to define and develop a Kubeflow solution for model management, which will make it easier to organize and find models and their artifacts. In addition, several contributors are submitting proposals on how to define data types for ML model and data, with the goal of driving wider metadata standards, and interoperability of models between ML platforms, clouds, and frameworks. The proposals are working to define an ontology for model and data types and tooling to search and organize that metadata.
Proposals from Kubeflow Pipelines contributors, the Model Management SIG, Seldon and a MLSpec from David Aronchick (Azure) are under discussion. Please find links to those proposals below:
- ML Data in Kubeflow Pipelines
- ML Spec from David Aronchick
- Model Management Proposal from Karl Schriek, SIG Tech Lead
- Seldon’s Proposal for Initial Metadata Types
EcoSystem: Seldon
Overall benefit: Deploy, Scale, Update models built with Kubeflow.
Overall description: Seldon handles scaling of production machine learning models and provides advanced machine learning capabilities out of the box including Advanced Metrics, Request Logging, Explainers, Outlier Detectors, A/B Tests, and Canaries.
Kubeflow 1.2 comes with Seldon’s 1.4 release. This release of Seldon adds further capabilities for model deployment and inferencing including the addition of batch and streaming interfaces to a deployed model. It also allows for fine grained control of how a deployed model interfaces with Kubernetes with the addition of KEDA and Pod Disruption Budget options. Finally, it begins a process of compatibility with KFServing by allowing the usage of the V2 Dataplane supported by Seldon, KFServing and NVIDIA Triton.
Version: 1.4.0
Feature Name: Stream and Batch support
Feature Description: Streaming support for native Kafka integration. Batch prediction support from and to cloud storage.
Feature Benefit: Allows Seldon users to interact with their models via RPC, Streaming or Batch as needed.
Feature Name: Extended kubernetes control via KEDA and PDBs
Feature Description: Allows fine grained control of deployed models via autoscaling with KEDA metrics and addition of pod disruption budgets.
Feature Benefit: Manage models at scale in a production cluster.
Feature Name: Alpha V2 Dataplane
Feature Description: Run custom python models using an updated python server along with support for the V2 Dataplane (NVIDIA Triton, KFServing, Seldon)
Feature Benefit: Utilize a standard powerful protocol that is supported cross project.
EcoSystem: Kale
Overall benefit: Kubeflow Workflow tool that simplifies ML pipeline building and versioning directly from a Notebook or IDE i.e. VSCode
Kale GitHub repo: https://github.com/kubeflow-kale/kale
Kale Tutorials: https://www.arrikto.com/tutorials/
Overall description: Kale lets you deploy Jupyter Notebooks that run on your laptop or on the cloud to Kubeflow Pipelines, without requiring any of the Kubeflow SDK boilerplate. You can define pipelines just by annotating Notebook’s code cells and clicking a deployment button in the Jupyter UI. Kale will take care of converting the Notebook to a valid Kubeflow Pipelines deployment, taking care of resolving data dependencies and managing the pipeline’s lifecycle
Feature Name: Dog Breed Classification example
Feature Description: Tutorial for simplified pipeline to build a model for Image Classification
Feature Benefit: Faster understanding of ML workflows to deliver models with hyperparameter tuning
Feature Name: Katib integration with Kale
Feature Description: Automated hyperparameter tuning and reproducible katib trials using pipelines
Feature Benefit: Better model accuracy and easy reproducibility and debugging
Feature Name: Pipeline Step Caching for Katib Trials using Kale’s integration with Rok
Feature Description: Kale recognizes when a pipeline step has been run before and fetches complete results from Rok and inserts into pipeline processing
Feature Benefit: Faster hyperparameter tuning, reduced infrastructure utilization
EcoSystem: Feast
Overall benefit: Feast allows teams to register, ingest, serve, and monitor machine learning features in production.
Working Group Meeting Notes: https://tinyurl.com/kf-feast-sig
Overall description: The latest release of Feast was a concerted effort by the Feast community to make Feast available in more environments than Google Cloud. We’ve removed all hard couplings to managed services and made it possible to run Feast both on AWS and locally.
Version: Feast 0.8
Feature Name: Support for AWS
Feature Description: Feast 0.8 now comes with support for deployment on AWS, with native support for job management on EMR, and support for both S3 and Kinesis as data sources.
Feature Benefit: Finally makes it possible for Kubeflow users on AWS to run Feast
Feature Name: Batch-only ingestion
Feature Description: Allows teams to ingest data into stores without passing the data through a stream.
Feature Benefit: Allows for a more performant ingestion compared to the stream-first approach.
Feature Name: Local-only mode
Feature Description: Makes it possible to run Feast without any external infrastructure, using only Docker Compose or Minikube
Feature Benefit: Lowers the barrier to entry for new users, and makes it easier to test and develop Feast
EcoSystem: On-Prem SIG
Description: The on-prem SIG was officially created during this release with the intent to develop best practices for Kubeflow deployment in on-prem installations. With the new release, the SIG has also secured testing infrastructure in order to provide a well-tested reference architecture.
SIG Meeting Notes: https://bit.ly/2LyTh14
Slack channel: https://kubeflow.slack.com/archives/C01C9NPD15H
Platform: AWS
Description: Better reliability, better testing coverage by enabling E2E tests for Kubeflow AWS deployment, better Kubeflow notebook user experience.
Platform: IBM
Description: Pipelines and Security have been the key focus for Kubeflow on IBM Cloud for this release. On the Pipelines side, Kubeflow Pipelines with Tekton is available for deployment on IBM Cloud Kubernetes Service and is included by default with Kubeflow deployment on IBM Cloud. On the security side, we have enabled integration with IBM Cloud AppId as an authentication provider instead of Dex. When using AppID, it delegates the identity provider to IBM Cloud with builtin identity providers (Cloud Directory, SAML, social log-in with Google or Facebook etc.) or custom providers. Additionally for securing the Kubeflow authentication with HTTPS we have provided integration instructions using the IBM Cloud Network Load Balancer.
Platform: GCP
Description: Better UX and reliability for installation and upgrade. Upgrade Cloud Config Connector in management cluster to latest.
Platform: Azure
Description: We added instructions for deploying Kubeflow with multi-tenancy backed by Azure Active Directory. Additionally, we documented the steps to replace the Metadata store with a managed Azure MySQL datatabase instance.
Platform: OpenShift
Description: Our focus for this release was to create the OpenShift stack that can install Kubeflow components on OpenShift 4.x . We architected the stack so users can pick and choose components they would like to install by adding or removing kustomizeConfig entries in the kfdef. Components currently supported are istio, single user pipeline, Jupyter notebooks with a custom Tensorflow notebook image, profile controller with custom image, Katib, pytorch and Tensorflow job operators and Seldon. You can install Kubeflow 1.2 on Openshift from the Open Data Hub community operator in OpenShift Catalog using the OpenShift kfdef.
Platform: MicroK8s
Description: Kubeflow is a built-in add-on to MicroK8s, and now includes Istio v1.5 as default.
Platform: MiniKF
Description: MiniKF is currently testing with Kubeflow 1.2 and will provide an updated MiniKF version based after validation testing and documentation has completed. Please find more information on MiniKF here: https://www.arrikto.com/get-started/ . You can also find tutorials that will guide you through end-to-end data science examples here: https://www.arrikto.com/tutorials