Introduction to Kubeflow MPI Operator and Industry Adoption
- Example API Spec
- Architecture
- Industry Adoption
- Ant Group
- Bloomberg
- Caicloud
- Iguazio
- Polyaxon
- Community and Call for Contributions
Kubeflow just announced its first major 1.0 release recently, which makes it easy for machine learning engineers and data scientists to leverage cloud assets (public or on-premise) for machine learning workloads. In this post, we’d like to introduce MPI Operator (docs), one of the core components of Kubeflow, currently in alpha, which makes it easy to run synchronized, allreduce-style distributed training on Kubernetes.
There are two major distributed training strategies nowadays: one based on parameter servers and the other based on collective communication primitives such as allreduce.
Parameter server based distribution strategy relies on centralized parameter servers for coordination between workers, responsible for collecting gradients from workers and sending updated parameters to workers. The diagram below shows the interaction between parameter servers and worker nodes under this distributed training strategy.
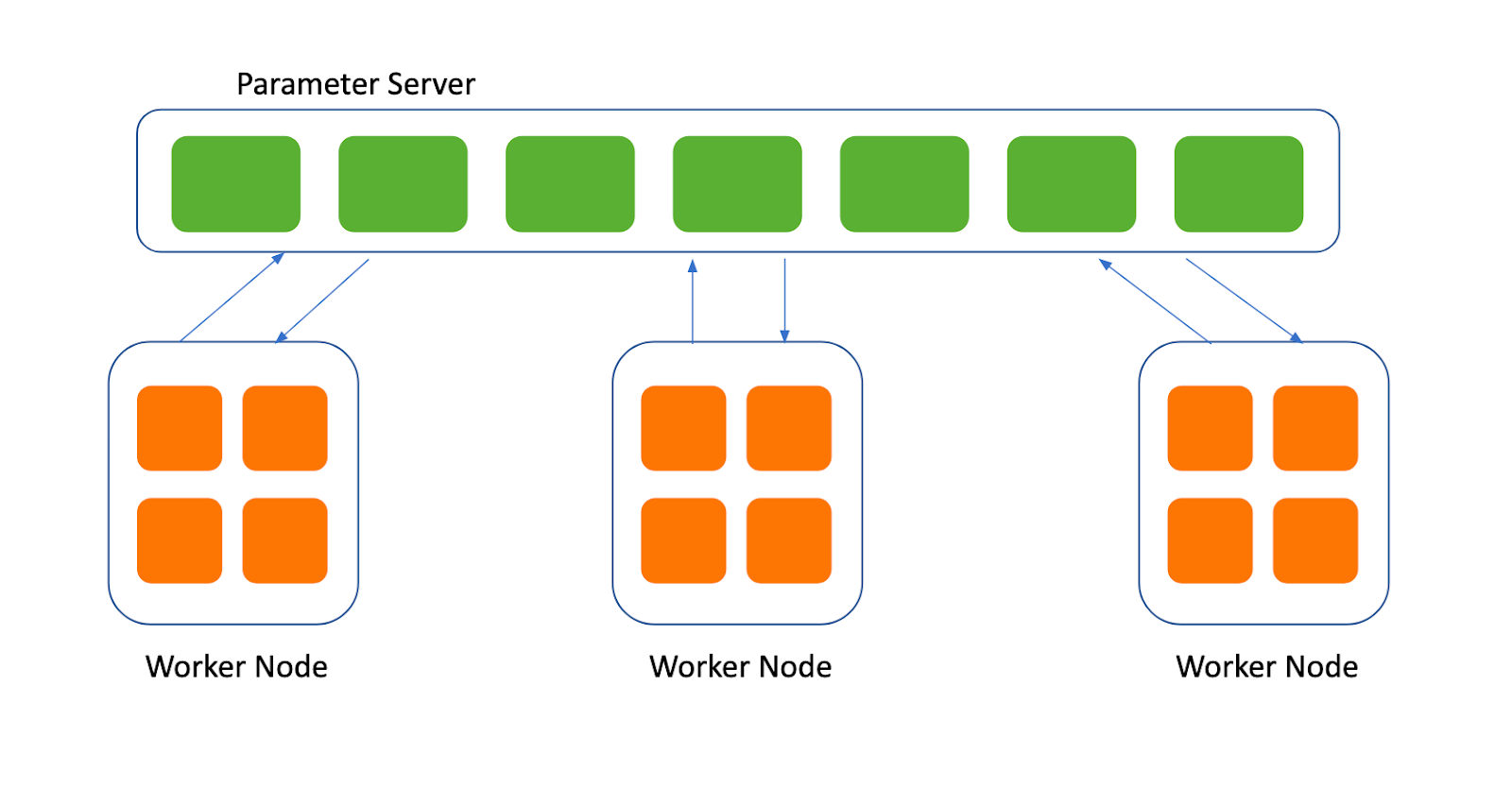
While distributed training based on parameter servers can support training very large models and datasets by adding more workers and parameter servers, there are additional challenges involved in order to optimize the performance:
-
It is not easy to identify the right ratio of the number of workers to the number of parameter servers. For example, if only a small number of parameter servers are used, network communication will likely become the bottleneck for training.
-
If many parameter servers are used, the communication may saturate network interconnects.
-
The memory quota of workers and parameter servers requires fine tuning to avoid out-of-memory errors or memory waste.
-
If the model could fit within the computational resources of each worker, additional maintenance and communication overheads are introduced when the model is partitioned to multiple parameter servers.
-
We need to replicate the model on each parameter server in order to support fault-tolerance, which requires additional computational and storage resources.
In contrast, distributed training based on collective communication primitives such as allreduce could be more efficient and easier to use in certain use cases. Under allreduce-based distributed training strategy, each worker stores a complete set of model parameters. In other words, no parameter server is needed. Allreduce-based distributed training could address many of the challenges mentioned above:
-
Each worker stores a complete set of model parameters, no parameter server is needed, so it’s straightforward to add more workers when necessary.
-
Failures among the workers can be recovered easily by restarting the failed workers and then load the current model from any of the existing workers. Model does not need to be replicated to support fault-tolerance.
-
The model can be updated more efficiently by fully leveraging the network structure and collective communication algorithms. For example, in ring-allreduce algorithm, each of the N workers only needs to communicate with two of its peer workers 2 * (N − 1) times to update all the model parameters completely.
-
Scaling up and down the number of workers is as easy as reconstructing the underlying allreduce communicator and re-assigning the ranks among the workers.
There are many existing technologies available that provide implementations for these collective communication primitives such as NCCL, Gloo, and many different implementations of MPI.
MPI Operator provides a common Custom Resource Definition (CRD) for defining a training job on a single CPU/GPU, multiple CPU/GPUs, and multiple nodes. It also implements a custom controller to manage the CRD, create dependent resources, and reconcile the desired states.

Unlike other operators in Kubeflow such as TF Operator and PyTorch Operator that only supports for one machine learning framework, MPI operator is decoupled from underlying framework so it can work well with many frameworks such as Horovod, TensorFlow, PyTorch, Apache MXNet, and various collective communication implementations such as OpenMPI.
For more details on comparisons between different distributed training strategies, various Kubeflow operators, please check out our presentation at KubeCon Europe 2019.
Example API Spec
We’ve been working closely with the community and industry adopters to improve the API spec for MPI Operator so it’s suitable for many different use cases. Below is an example:
apiVersion: kubeflow.org/v1alpha2
kind: MPIJob
metadata:
name: tensorflow-benchmarks
spec:
slotsPerWorker: 1
cleanPodPolicy: Running
mpiReplicaSpecs:
Launcher:
replicas: 1
template:
spec:
containers:
- image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
command:
- mpirun
- python
- scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py
- --model=resnet101
- --batch_size=64
- --variable_update=horovod
Worker:
replicas: 2
template:
spec:
containers:
- image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
resources:
limits:
nvidia.com/gpu: 1
Note that MPI Operator provides a flexible but user-friendly API that’s consistent across other Kubeflow operators.
Users can easily customize their launcher and worker pod specs by modifying the relevant sections in the template. For example, customizing to use various types of computational resources such as CPUs, GPUs, memory, etc.
In addition, below is an example spec that performs distributed TensorFlow training job using ImageNet data in TFRecords format stored in a Kubernetes volume:
apiVersion: kubeflow.org/v1alpha2
kind: MPIJob
metadata:
name: tensorflow-benchmarks
spec:
slotsPerWorker: 1
cleanPodPolicy: Running
mpiReplicaSpecs:
Launcher:
replicas: 1
template:
spec:
containers:
- image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
command:
- mpirun
- python
- scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py
- --model=resnet101
- --batch_size=64
- --variable_update=horovod
Worker:
replicas: 2
template:
spec:
containers:
- image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
resources:
limits:
nvidia.com/gpu: 1
Architecture
MPI Operator contains a custom controller that listens for changes in MPIJob resources. When a new MPIJob is created, the controller goes through the following logical steps:
- Create a ConfigMap that contains:
-
A helper shell script that can be used by mpirun in place of ssh. It invokes kubectl exec for remote execution.
-
A hostfile that lists the pods in the worker StatefulSet (in the form of ${job-id}-worker-0, ${job-id}-worker-1, …), and the available slots (CPUs/GPUs) in each pod.
-
Create the RBAC resources (Role, ServiceAccount, RoleBinding) to allow remote execution (pods/exec).
-
Wait for the worker pods to be ready.
-
Create the launcher job. It runs under the ServiceAccount created in step 2, and sets up the necessary environment variables for executing mpirun commands remotely. The kubectl binary is delivered to an emptyDir volume through an init container.
-
After the launcher job finishes, set the replicas to 0 in the worker StatefulSet.
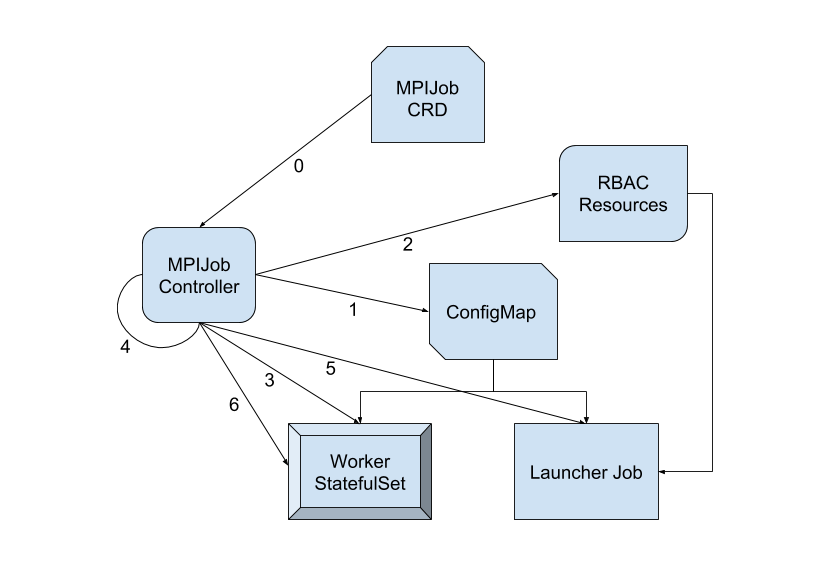
For more details, please check out the design doc for MPI Operator.
Industry Adoption
At the time of writing, there are 13 disclosed industry adopters and many others who’ve been working closely with the community to reach where we are today. We’d like to showcase some of the use cases of MPI Operator in several companies. If your company would like to be included in the list of adopters, please send us a pull request on GitHub!
Ant Group
At Ant Group, we manage Kubernetes clusters with tens of thousands of nodes and have deployed the MPI Operator along with other Kubeflow operators. The MPI Operator leverages the network structure and collective communication algorithms so that users don’t have to worry about the right ratio between the number of workers and parameter servers to obtain the best performance. Users can focus on building out their model architectures without spending time on tuning the downstream infrastructure for distributed training.
The models produced have been widely deployed in production and battle-tested in many different real life scenarios. One notable use case is Saofu — a mobile app for users to scan any “福” (Chinese character that represents fortune) through augmented reality to enter a lucky draw where each user would receive a virtual red envelope with a portion of a significant amount of money.
Bloomberg
Bloomberg, the global business and financial information and news leader, possesses an enormous amount of data — from historical news to real-time market data and everything in between. Bloomberg’s Data Science Platform was built to allow the company’s internal machine learning engineers and data scientists to more easily leverage data and algorithmic models in their daily work, including when training jobs and automatic machine learning models used in the state-of-the-art solutions they’re building.
“The Data Science Platform at Bloomberg offers a TensorFlowJob CRD similar to Kubeflow’s own TFJob, enabling the company’s data scientists to easily train neural network models. Recently, the Data Science Platform team enabled Horovod-based distributed training in its TensorFlowJob via the MPI Operator as an implementation detail. Using MPIJob in the back-end has allowed the Bloomberg Data Science Platform team to quickly offer its machine learning engineers a robust way to train a BERT model within hours using the company’s large corpus of text data’’, says Chengjian Zheng, software engineer from Bloomberg.
Caicloud
Caicloud Clever is an artificial intelligence cloud platform based on Caicloud container cloud platform with powerful hardware resource management and efficient model development capabilities. Caicloud products have been deployed in many 500 China Fortune companies.
“Caicloud Clever supports multiple frameworks of AI model training including TensorFlow, Apache MXNet, Caffe, PyTorch with the help of Kubeflow tf-operator, pytorch-operator and others”, says Ce Gao, AI infrastructure engineer from Caicloud Clever team. “While RingAllReduce distributed training support is requested for improved customer maturity.”
Kubeflow MPI operator is a Kubernetes Operator for allreduce-style distributed training. Caicloud Clever team adopts MPI Operator’s v1alpha2 API. The Kubernetes native API makes it easy to work with the existing systems in the platform.
Iguazio
Iguazio provides a cloud-native data science platform with emphasis on automation, performance, scalability, and use of open-source tools.
According to Yaron Haviv, the Founder and CTO of Iguazio, “We evaluated various mechanisms which will allow us to scale deep learning frameworks with minimal developer effort and found that using the combination of Horovod with the MPI Operator over Kubernetes is the best tool for the job since it enable horizontal scalability, supports multiple frameworks such as TensorFlow and PyTorch and doesn’t require too much extra coding or the complex use of parameter servers.”
Iguazio have integrated the MPI Operator into its managed service offering and its fast data layer for maximum scalability, and work to simplify the usage through open source projects like MLRun (for ML automation and tracking). Check out this blog post with an example application that demonstrates Iguazio’s usage of the MPI Operator.
Polyaxon
Polyaxon is a platform for reproducible and scalable machine learning on Kubernetes, it allows users to iterate faster on their research and model creation. Polyaxon provides a simple abstraction for data scientists and machine learning engineers to streamline their experimentation workflow, and provides a very cohesive abstraction for training and tracking models using popular frameworks such as Scikit-learn, TensorFlow, PyTorch, Apache MXNet, Caffe, etc.
“Several Polyaxon users and customers were requesting an easy way to perform an allreduce-style distributed training, the MPI Operator was the perfect solution to provide such abstraction. Polyaxon is deployed at several companies and research institutions, and the public docker hub has over 9 million downloads.”, says Mourad Mourafiq, the Co-founder of Polyxagon.
Community and Call for Contributions
We are grateful for over 28 individual contributors from over 11 organizations, namely Alibaba Cloud, Amazon Web Services, Ant Group, Bloomberg, Caicloud, Google Cloud, Huawei, Iguazio, NVIDIA, Polyaxon, and Tencent, that have contributed directly to MPI Operator’s codebase and many others who’ve filed issues or helped resolve them, asked and answered questions, and were part of inspiring discussions. We’ve put together a roadmap that provides a high-level overview of where the MPI Operator will grow in future releases and we welcome any contributions from the community!
We could not have achieved our milestones without an incredibly active community. Check out our community page to learn more about how to join the Kubeflow community!
Originally published at https://terrytangyuan.github.io on March 17, 2020.